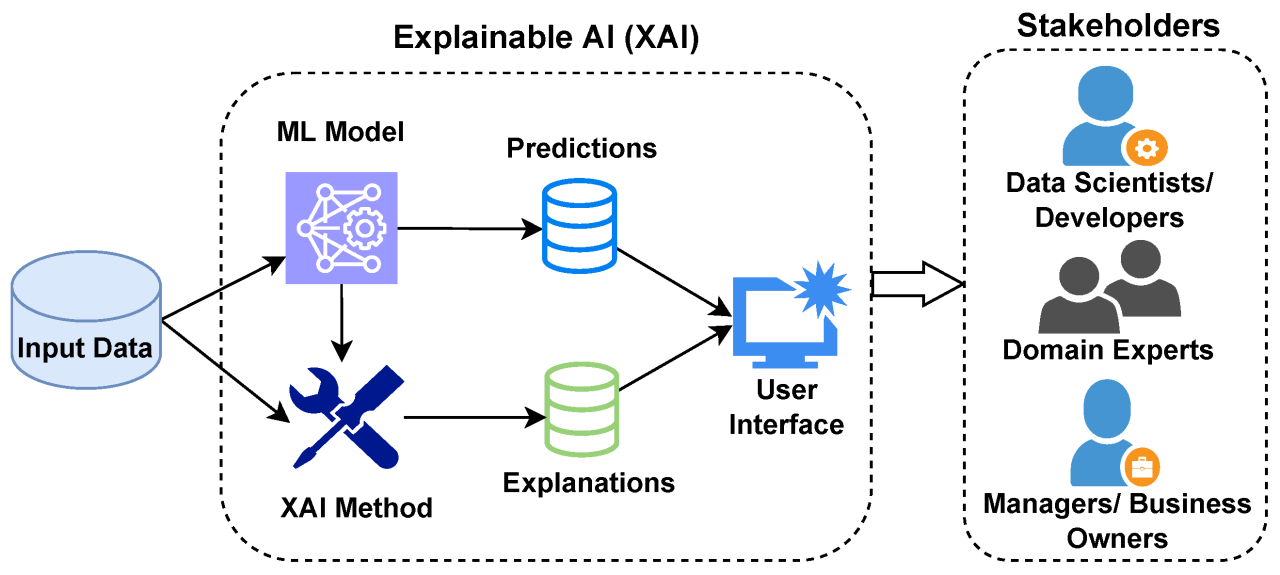
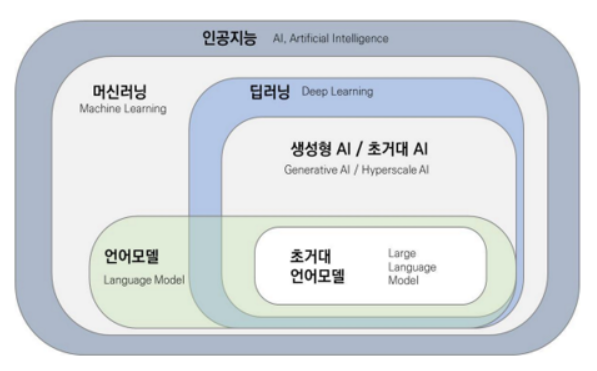
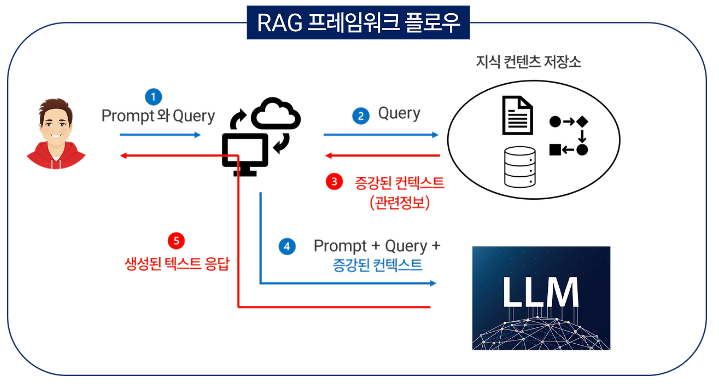
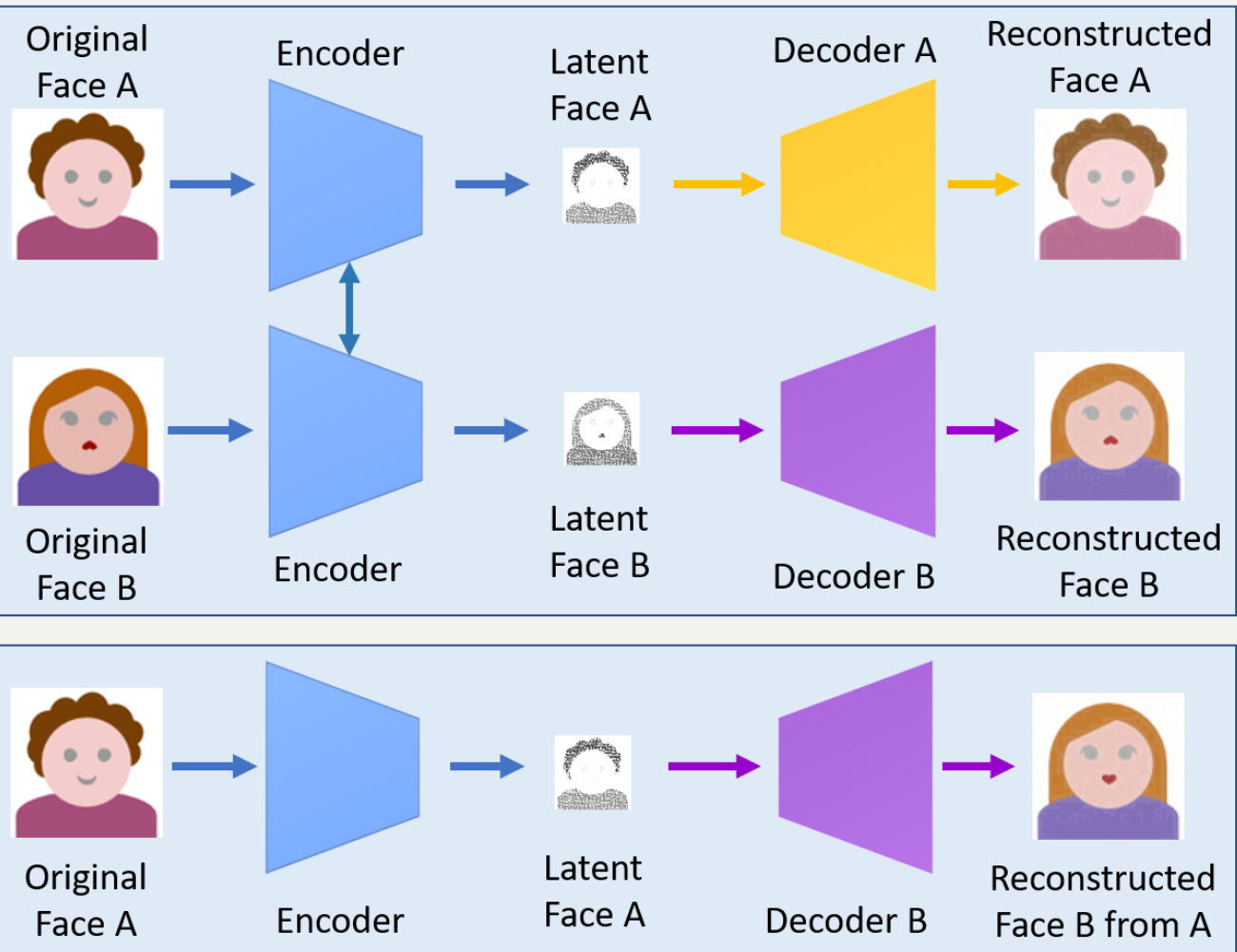
Ⅰ. 머신러닝 모델 개발 자동화, AutoML의 개요가. AutoML 개념- 머신러닝 모델을 학습하고 배포하는 과정을 자동화하여 필요한 인력, 비용, 시간을 줄이고 최적의 성능을 찾아내는 프로세스 나. AutoML 등장배경1. 머신러닝 생선성 강화 필요: AI 플랫폼 기반 머신러닝 파이프라인 서비스 생산성 강화2. 도메인 전문가 부족: 알고리즘 개선에 필요한 도메인 전문가 부족3. 전이학습 기반 한계: 학습 모델 재사용에 따른 오류 방지 Ⅱ. AutoML 구성 및 구성요소가. AutoML 구성도- 데이터 특징 추출, 하이퍼파라미터 최적화, 신경망 아키텍처 탐색 프로세스 자동화 나. AutoML 구성요소별 주요기법구성요소주요 기법설명하이퍼파라미터최적화- 그리드 탐색- 랜덤 탐색- 베이지안 탐색- 학습률, ..