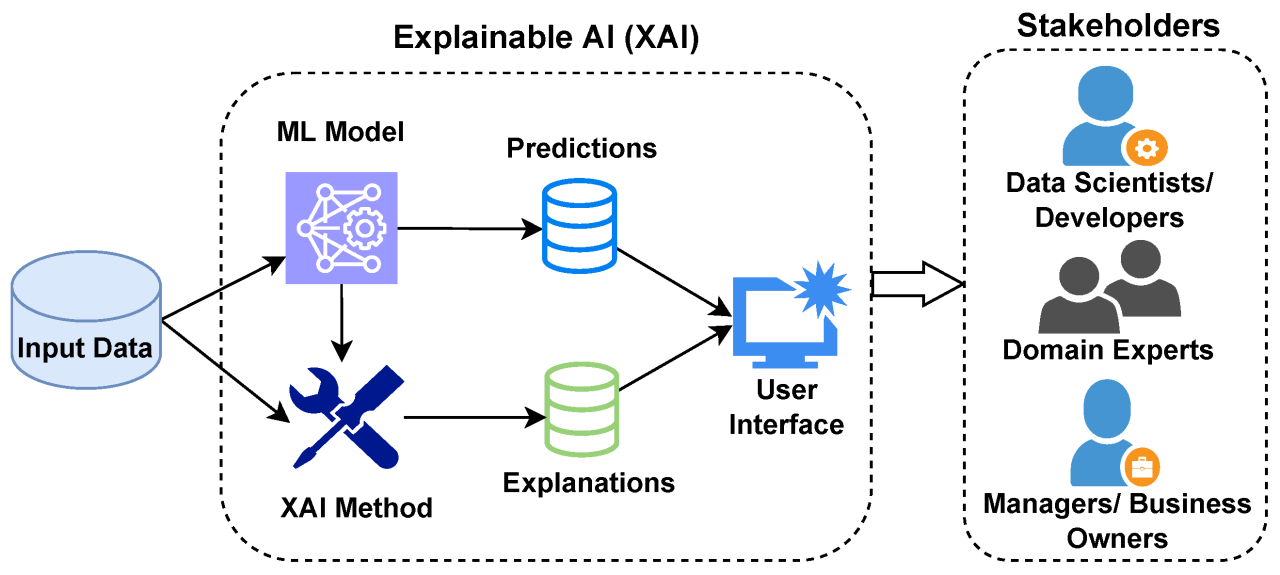
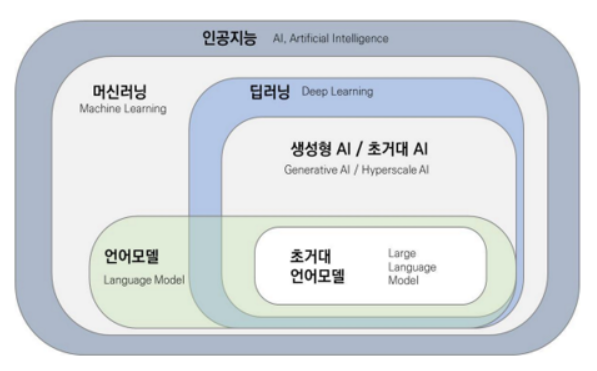
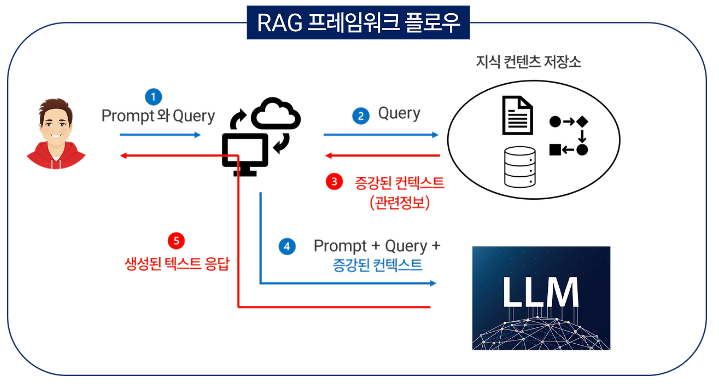
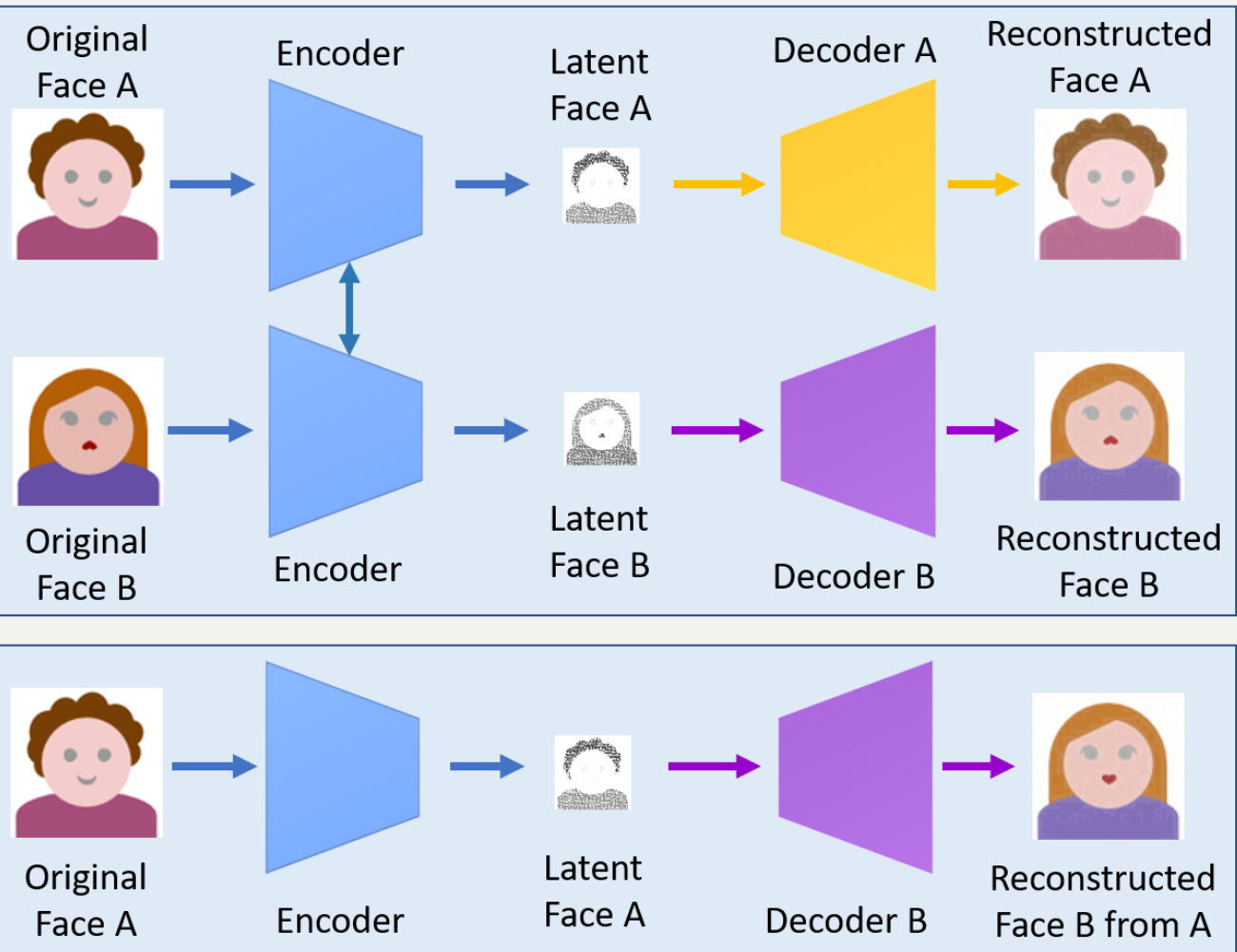
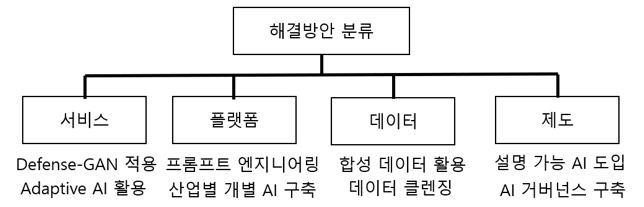
Ⅰ. 설명 가능한 인공지능, XAI의 개요가. XAI의 개념- 인공지능 모델의 최종 결과물에 대해서 추론 과정과 원인에 대한 설명이 가능하도록 하여 사용자가 쉽게 이해할 수 있도록 하는 인공지능 기술 나. XAI의 등장 배경인공지능 영향력 확산- 국가의 경제성장 기여- 금융, 교통, 교육 등 전 분야 의사결정 지원인공지능 역기능 사례 증가- 블랙박스 모델에 의한 결과 해석 불가XAI로 문제 해결- 의사결정 투명성 확보- 공정성, 신뢰성 보장 Ⅱ. XAI 구현 기술구분세부 기술설명기존 학습모델변경 기술역 합성곱 신경망- 기존 학습 모델에 역산 과정 추가 및 수정추론 및 시각화- 합성곱 신경망의 학습 과정 역산으로 결과 영향 요소 추론 및 시각화새로운 학습모델기술확률적 AND-OR 그래프- 원인, 결과 도출..