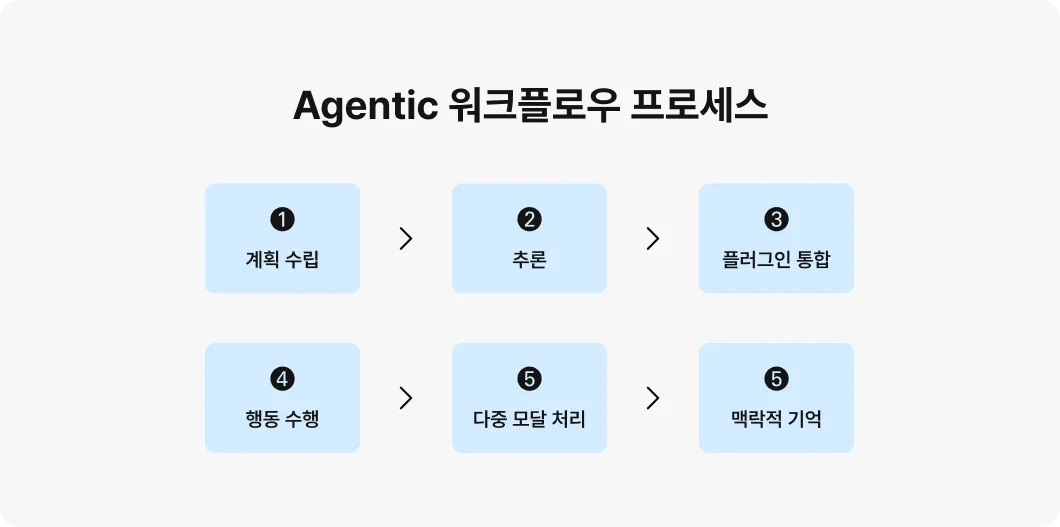
Ⅰ. 자율적인 의사결정을 추구하는 AI, 에이전틱 AI의 개요가. 에이전틱 AI의 정의- 자율적으로 복잡한 목표를 설정하고 환경과 상호작용하여 최소한의 인간 감독으로 작업을 수행하는 인공지능 시스템 나. 에이전틱 AI의 특징자율성- 인간 개입 없이 독립적으로 작동하고 목표 달성적응성- 변화하는 환경에 맞춰 계획 조정, 새로운 상황에 적응언어 이해- 자연어 이해, 해석, 사용자와의 상호작용워크플로우 최적화- 복잡한 비즈니스 워크플로우 효율적으로 조직 및 관리 Ⅱ. 에디전틱 AI의 프로세스프로세스설명계획 수립에이전트는 하위 목표를 설정하고 워크플로우 설계추론대안을 분석, 의사결정 내리기 전에 논리적 추론 실행플러그인 통합모듈형 컴포넌트를 통합하여 전문화된 작업 수행행동 수행독립적으로 운영 작업을 수행다중 모..