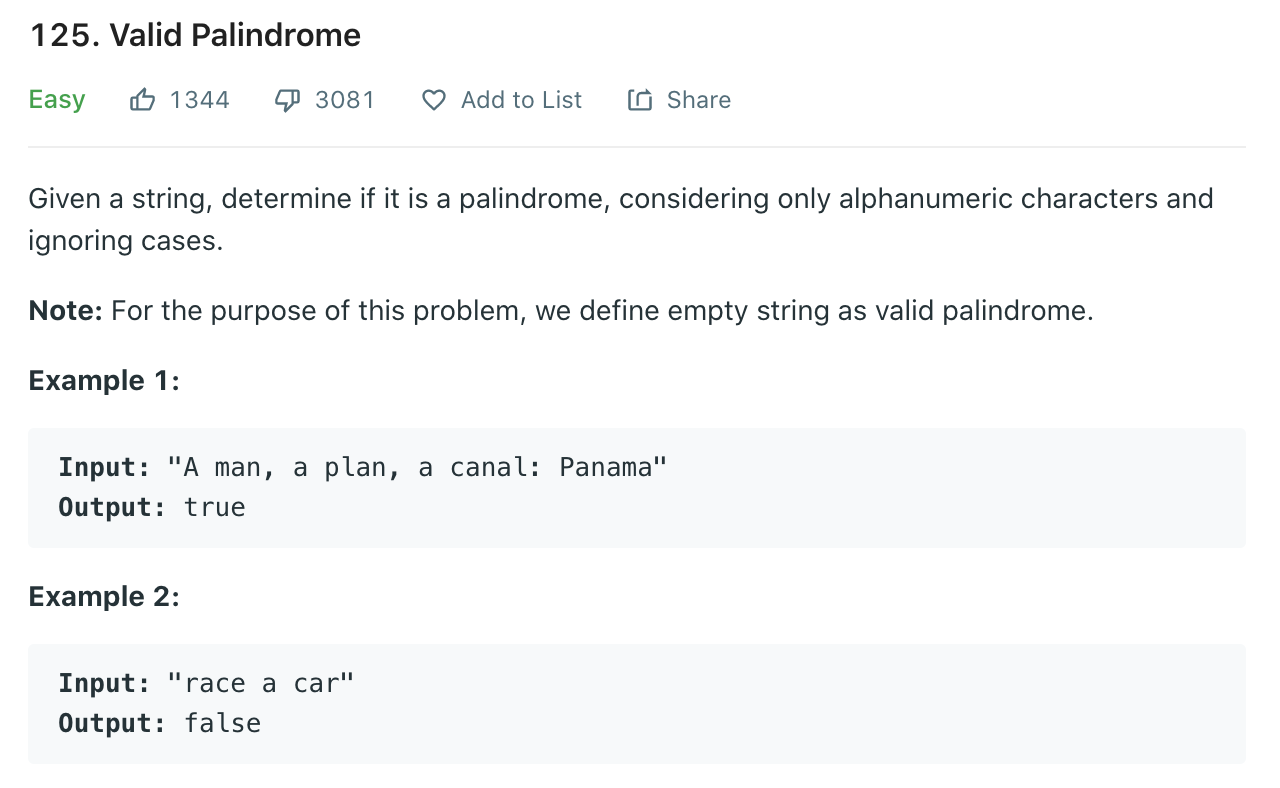
Problem) 간단한 문자열 문제입니다. 코딩 문제로 문자열과 정규식 관련 문제를 은근히 자주 마주칠 수 있는데요. 이번 문제를 통해서 다시 한번 문자열 관련 다양한 처리 방법들에 대해서 정리해보면 좋을 것 같네요. Solution) # 문자열 활용 솔류션 class Solution: def isPalindrome(self, s: str) -> bool: strs = [] for char in s: if char.isalnum(): strs.append(char.lower()) while len(strs) > 1: if strs.pop(0) != strs.pop(): return False return True # 정규식 활용 솔류션 import re class Solution: def isPalind..