반응형
Ⅰ. 복수개의 모델 조합, 앙상블 기법의 개요

- 복수의 약한 분류기를 생성하고 그 예측을 결합함으로써 더 정확한 최종 예측을 도출하는 기법
Ⅱ. 랜덤 샘플 데이터 학습, Bagging
가. Bagging의 정의
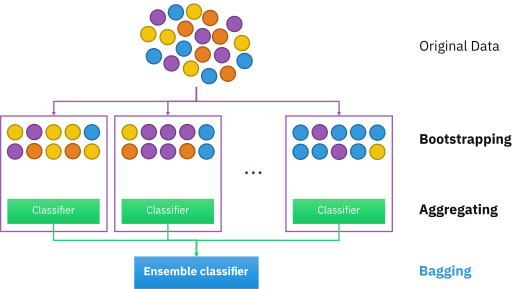 |
|
| 정의 | Bootstrap Aggregating, 여러 개의 동일한 모델을 독립적으로 랜덤 샘플 데이터를 학습시켜 각각의 예측을 결합하여 최종 예측 수행하는 앙상블 기법 |
나. Bagging의 주요 과정
| 과정 | 설명 |
| 부트스트랩 샘플링 | - 전체 데이터셋에서 중복 허용 랜덤 샘플링 수행 - 복수의 훈련 데이터셋 생성 |
| 독립 모델 학습 | - 생성한 훈련 데이터로 독립 모델 학습 - 동일한 알고리즘으로 서로 다른 데이터 학습 |
| 예측 결합 | - 예측 결과 결합하여 최종 예측 - 회귀 문제는 평균, 분류 문제는 투표를 통해 결정 |
- 전체 데이터 중 샘플링 되지 않아 학습되지 않는 OOB(Out-of-Bag) 샘플 문제 존재
Ⅲ. 순차 학습 가중치 활용, Boosting
가. Boosting의 정의
 |
|
| 정의 | 여러개의 약한 학습기를 순차적으로 학습하고 잘못 예측한 데이터에 가중치를 부여해 오류 개선하는 앙상블 기법 |
나. Boosting의 주요 과정
| 과정 | 설명 |
| 약한 학습기 학습 | - 각 단계 순차적으로 약한 학습기 학습 - 주로 의사결정트리 사용 |
| 가중치 업데이트 | - 초기 모든 데이터 동일한 가중치 부여 - 각 모델은 이전 모델의 잘못 예측 데이터에 높은 가중치 부여 |
| 연속적 학습 | - 이전 모델 오차 보완 위한 새로운 약한 학습기 추가 학습 - 오차에 집중하여 가중치 조절 학습 |
| 최종 결합 | - 각 모델 예측에 가중치 부여하여 최종 예측 |
- 순차 학습 진행으로 인해 모델 학습 속도가 느리다
Ⅳ. 예측치 재학습, Stacking
가. Stacking의 정의
 |
|
| 정의 | 여러개의 개별 모델이 예측한 데이터를 다시 메타 데이터셋으로 최종 모델을 학습하여 결과 예측하는 앙상블 기법 |
나. Stacking의 중요 과정
| 주요 과정 | 설명 |
| 기본 모델 학습 | - 원본 전체 데이터를 크로스 벨리데이션으로 나누어 학습 데이터 생성 - 생성한 학습데이터로 기본 모델 학습 |
| 메타 데이터셋 생성 | - 기본 모델의 예측값들을 평균하여 최종 모델 학습 데이터 생성 |
| 최종 모델 학습 | - 메타 데이터셋으로 최종 모델 학습하여 최종 예측 |
- 기본 모델들이 전체 데이터를 학습하기 때문에 오버피팅 문제 존재
반응형
'IT 기술 > DB' 카테고리의 다른 글
| 분산 데이터베이스 투명성 (0) | 2024.10.02 |
|---|---|
| DBMS 병행 제어 (0) | 2024.10.01 |
| 데이터 모델링의 4단계 (0) | 2024.10.01 |
| NoSQL CAP 이론 (0) | 2024.10.01 |
| 함수적 종속성(FD), 4, 5차 정규화, DB Table Partitioning, 쿼리 오프로딩 (0) | 2024.07.04 |