반응형
Ⅰ. 컴퓨터 비전 분야에 Transformer 적용, ViT의 개념
- Transformer 구조를 Vision 분야에 적용해 대량의 이미지 데이터 학습 및 이미지 분류하는 모델
Ⅱ. ViT의 개념도 및 매커니즘
가. ViT의 개념도
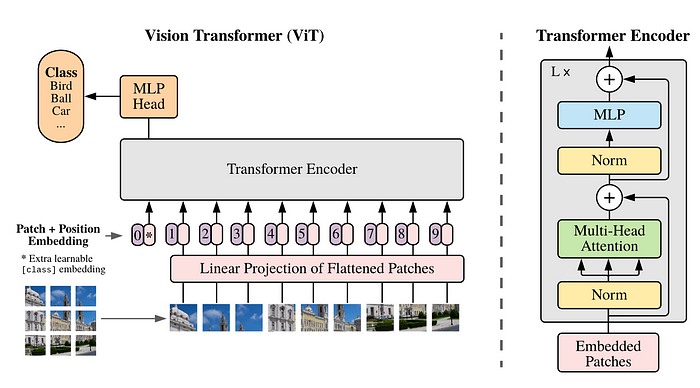
- 이미지를 패치(16*16) 분할하고 각 패치의 선형 임베딩을 Transformer의 입력으로 사용
나. ViT의 매커니즘
| 단계 | 설명 |
| 이미지 패치분할 | - 입력 이미지를 고정된 크기의 패치로 분할 |
| 선형 임베딩 | - 각 패치는 선형 투영을 통해 벡터 형태로 변환 |
| 위치 임베딩 추가 | - 패치의 위치 정보를 유지하기 위해 위치 임베딩 추가 - 순서 정보를 알 수 없기 때문에 위치 정보 필요 |
| Transformer 인코더 | - 패치의 선형 임베딩과 위치 임베딩 결합 - 결합된 벡터를 Transformer 인코더에 입력 |
| CLS 토큰 | - 분류 작업 위한 CLS 토큰 추가 - 토큰은 전체 이미지에 대한 정보 취합 |
| 분류 | - Transformer 인코더 출력에서 분류 토큰 벡터 사용 분류 |
반응형
'IT 기술 > 인공지능' 카테고리의 다른 글
| 파운데이션 모델 (1) | 2024.12.11 |
|---|---|
| 워드 임베딩과 기법 (0) | 2024.12.11 |
| 파인 튜닝과 프롬프트 엔지니어링 (1) | 2024.12.11 |
| 적응형 AI(Adaptive AI) (3) | 2024.12.11 |
| 인공지능 악용 (0) | 2024.12.10 |