프로그램의 실행 속도는 프로그래밍의 아주 중요한 요소입니다. Python에서 프로세스 기반의 병렬 처리를 통해 실행 속도를 향상 시킬 수 있는 방법에 대해서 알아보겠습니다. Python에서는 병렬 처리를 위해 multiprocessing 패키지를 제공합니다. multiprocessing에는 대표적으로 Pool과 Process가 있지만 이번 글에서는 Process에 대해서만 다루도록 하겠습니다. multiprocessing.process Process는 미리 정의한 함수를 하나의 프로세스에 할당하여 실행합니다. 이때, 각 프로세스마다 적당한 인자값을 할당하여 실행할 수 있습니다. [example code] import os from multiprocessing import Process def add_on..
분류 전체보기
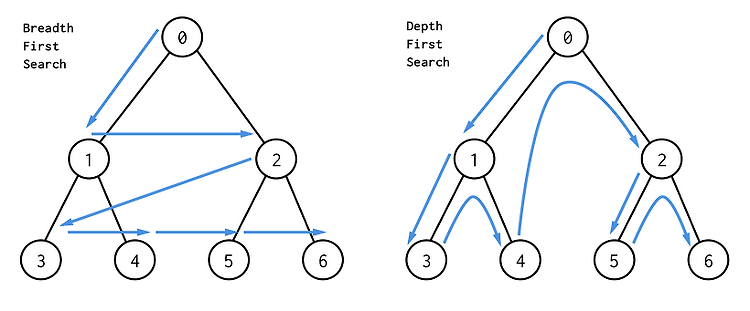
프로그래밍에 자주 사용되는 대표적인 자료구조에는 "그래프"가 있습니다. 오늘 포스팅에서는 그래프를 탐색하는 알고리즘 2가지 DFS와 BFS에 대해서 알아보도록 하겠습니다. 그래프는 정점과 간선으로 이루어져 있는데 간선을 통해서 모든 정점을 방문하는 것을 그래프를 탐색한다고 합니다. 위에서 언급했듯이 그래프 탐색 알고리즘에는 대표적으로 깊이 우선 탐색(DFS), 너비 우선 탐색(BFS)가 있습니다. 각각의 알고리즘에 대해서 자세히 알아보도록 하겠습니다. 위 그림을 보시면 두 알고리즘의 차이에 대해서 직관적으로 이해하실 수 있습니다. 각 알고리즘의 명칭에서도 볼 수 있듯이 깊이(자식)를 우선으로 탐색하느냐 아니면 너비(형제)를 우선으로 탐색하느냐의 차이가 있습니다. 1. 깊이 우선 탐색깊이 우선 탐색 (De..